Machen Sie eine Access-Exkursion durch SQL Server
Nachdem Sie Ihre Daten von Access zu SQL Server migriert haben, verfügen Sie nun über eine Client/Server-Datenbank, die eine lokale oder hybride Azure-Cloud-Lösung sein kann. In jedem Fall ist Access jetzt die Präsentationsschicht und SQL Server die Datenschicht. Jetzt ist ein guter Zeitpunkt, um Aspekte Ihrer Lösung zu überdenken, insbesondere Abfrageleistung, Sicherheit und Geschäftskontinuität, damit Sie Ihre Datenbanklösung verbessern und skalieren können.
Für einen Access-Benutzer kann es entmutigend sein, zuerst die SQL Server- und Azure-Dokumentation kennenzulernen. Dazu bedarf es eines Reiseleiters, der Sie durch die für Sie wichtigen Highlights führt. Nach Abschluss dieser Exkursion sind Sie bereit, die Fortschritte in der Datenbanktechnologie zu erkunden und eine längere Reise zu unternehmen.
In diesem Artikel
Datenbankmanagement Fördern Sie die Geschäftskontinuität Umgang mit Datenschutzbedenken | Anfragen und ähnliches Verbessern Sie die Abfrageleistung | Datentypen | Verschiedene |
Fördern Sie die Geschäftskontinuität
Sie möchten Ihre Access-Lösung mit minimalen Unterbrechungen am Laufen halten, aber Ihre Optionen mit einer Access-Back-End-Datenbank sind begrenzt. Das Sichern Ihrer Access-Datenbank ist für den Schutz Ihrer Daten unerlässlich, erfordert jedoch, dass Ihre Benutzer offline geschaltet werden. Dann gibt es ungeplante Ausfallzeiten, die durch Hardware-/Software-Wartungs-Upgrades, Netzwerk- oder Stromausfälle, Hardwarefehler, Sicherheitsverletzungen oder sogar Cyberangriffe verursacht werden. Um Ausfallzeiten und Auswirkungen auf Ihr Unternehmen zu minimieren, können Sie eine SQL Server-Datenbank sichern, während sie verwendet wird. Darüber hinaus bietet SQL Server auch Strategien für Hochverfügbarkeit (HA) und Notfallwiederherstellung (DR). Diese beiden kombinierten Technologien werden als HADR bezeichnet. Weitere Informationen finden Sie unter Business Continuity und Datenbankwiederherstellung und Drive Business Continuity mit SQL Server (E-Book) .
Sicherung während des Gebrauchs
SQL Server verwendet einen Onlinesicherungsprozess, der stattfinden kann, während die Datenbank ausgeführt wird. Sie können eine vollständige Sicherung, eine Teilsicherung oder eine Dateisicherung durchführen. Ein Backup kopiert Daten und Transaktionsprotokolle, um einen vollständigen Wiederherstellungsvorgang sicherzustellen. Beachten Sie insbesondere bei einer lokalen Lösung die Unterschiede zwischen einfachen und vollständigen Wiederherstellungsoptionen und wie sie sich auf das Wachstum des Transaktionsprotokolls auswirken. Weitere Informationen finden Sie unter Wiederherstellungsmodelle .
Die meisten Sicherungsvorgänge werden sofort ausgeführt, mit Ausnahme von Dateiverwaltungs- und Datenbankverkleinerungsvorgängen. Wenn Sie dagegen versuchen, eine Datenbankdatei zu erstellen oder zu löschen, während ein Sicherungsvorgang ausgeführt wird, schlägt der Vorgang fehl. Weitere Informationen finden Sie unter Sicherungsübersicht .
HADR
Die beiden gängigsten Techniken zum Erzielen von Hochverfügbarkeit und Geschäftskontinuität sind Spiegelung und Clustering. SQL Server integriert Spiegelungs- und Clustertechnologie mit „Always On Failover Cluster Instances" und „Always On Availability Groups".
Spiegelung ist eine Kontinuitätslösung auf Datenbankebene, die ein nahezu sofortiges Failover unterstützt, indem eine Standby-Datenbank, eine vollständige Kopie oder Spiegelung der aktiven Datenbank auf separater Hardware verwaltet wird. Es kann in einem synchronen (hohen Sicherheits-) Modus arbeiten, in dem eine eingehende Transaktion gleichzeitig an alle Server übertragen wird, oder in einem asynchronen (Hochleistungs-) Modus, in dem eine eingehende Transaktion an die aktive Datenbank und dann an einige übertragen wird vorbestimmten Punkt auf den Spiegel kopiert. Die Spiegelung ist eine Lösung auf Datenbankebene und funktioniert nur mit Datenbanken, die das vollständige Wiederherstellungsmodell verwenden.
Clustering ist eine Lösung auf Serverebene, die Server zu einem einzigen Datenspeicher kombiniert, der für den Benutzer wie eine einzelne Instanz aussieht. Benutzer verbinden sich mit der Instanz und müssen nie wissen, welcher Server in der Instanz gerade aktiv ist. Wenn ein Server ausfällt oder zu Wartungszwecken offline geschaltet werden muss, ändert sich die Benutzererfahrung nicht. Jeder Server im Cluster wird vom Cluster-Manager mithilfe eines Heartbeats überwacht, sodass er erkennt, wenn der aktive Server im Cluster offline geht, und versucht, nahtlos auf den nächsten Server im Cluster umzuschalten, obwohl es beim Umschalten eine variable Zeitverzögerung gibt das passiert.
Weitere Informationen finden Sie unter Always On-Failoverclusterinstanzen und Always On-Verfügbarkeitsgruppen: eine Lösung für hohe Verfügbarkeit und Notfallwiederherstellung .
SQL Server-Sicherheit
Obwohl Sie Ihre Access-Datenbank schützen können, indem Sie das Trust Center verwenden und die Datenbank verschlüsseln, verfügt SQL Server über erweiterte Sicherheitsfunktionen. Sehen wir uns drei Funktionen an, die sich für den Access-Benutzer auszeichnen. Weitere Informationen finden Sie unter Sichern von SQL Server .
Datenbankauthentifizierung
Es gibt vier Datenbankauthentifizierungsmethoden in SQL Server, die Sie jeweils in einer ODBC-Verbindungszeichenfolge angeben können. Weitere Informationen finden Sie unter Verknüpfen mit oder Importieren von Daten aus einer Azure SQL Server-Datenbank . Jede Methode hat ihre eigenen Vorteile.
Integrierte Windows-Authentifizierung Verwenden Sie Windows-Anmeldeinformationen für die Benutzervalidierung, Sicherheitsrollen und die Beschränkung von Benutzern auf Funktionen und Daten. Sie können Domänenanmeldeinformationen nutzen und Benutzerrechte in Ihrer Anwendung einfach verwalten. Geben Sie optional einen Service Principal Names (SPNs) ein. Weitere Informationen finden Sie unter Wählen Sie einen Authentifizierungsmodus aus.
SQL Server-Authentifizierung Benutzer müssen sich mit Anmeldeinformationen verbinden, die in der Datenbank eingerichtet wurden, indem sie beim ersten Zugriff auf die Datenbank in einer Sitzung die Anmelde-ID und das Kennwort eingeben. Weitere Informationen finden Sie unter Wählen Sie einen Authentifizierungsmodus aus.
Integrierte Azure Active Directory-Authentifizierung Stellen Sie mithilfe von Azure Active Directory eine Verbindung mit der Azure SQL Server-Datenbank her. Nachdem Sie die Azure Active Directory-Authentifizierung konfiguriert haben, sind keine zusätzlichen Anmeldedaten und Kennwörter erforderlich. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit SQL-Datenbank mithilfe der Azure Active Directory-Authentifizierung .
Active Directory-Kennwortauthentifizierung Verbinden Sie sich mit Anmeldeinformationen, die in Azure Active Directory eingerichtet wurden, indem Sie den Anmeldenamen und das Kennwort eingeben. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit SQL-Datenbank mithilfe der Azure Active Directory-Authentifizierung .
Tipp Verwenden Sie Threat Detection, um Warnungen zu anomalen Datenbankaktivitäten zu erhalten, die auf potenzielle Sicherheitsbedrohungen für eine Azure SQL Server-Datenbank hinweisen. Weitere Informationen finden Sie unter SQL-Datenbank-Bedrohungserkennung .
Anwendungssicherheit
SQL Server verfügt über zwei Sicherheitsfeatures auf Anwendungsebene, die Sie mit Access nutzen können.
Dynamische Datenmaskierung Verbergen Sie vertrauliche Informationen, indem Sie sie vor nicht privilegierten Benutzern maskieren. Beispielsweise können Sie Sozialversicherungsnummern teilweise oder vollständig maskieren.
 Eine partielle Datenmaske |  Eine vollständige Datenmaske |
Es gibt mehrere Möglichkeiten, eine Datenmaske zu definieren und sie auf verschiedene Datentypen anzuwenden. Die Datenmaskierung ist richtliniengesteuert auf Tabellen- und Spaltenebene für eine definierte Gruppe von Benutzern und wird in Echtzeit auf Abfragen angewendet. Weitere Informationen finden Sie unter Dynamische Datenmaskierung .
Sicherheit auf Zeilenebene Mithilfe der Sicherheit auf Zeilenebene können Sie den Zugriff auf bestimmte Datenbankzeilen mit vertraulichen Informationen basierend auf Benutzermerkmalen steuern. Das Datenbanksystem wendet diese Zugriffsbeschränkungen an und dies macht das Sicherheitssystem zuverlässiger und robuster.

Es gibt zwei Arten von Sicherheitsprädikaten:
Ein Filterprädikat filtert Zeilen aus einer Abfrage. Der Filter ist transparent, und der Endbenutzer bemerkt keine Filterung.
Ein Blockprädikat verhindert eine nicht autorisierte Aktion und löst eine Ausnahme aus, wenn die Aktion nicht ausgeführt werden kann.
Weitere Informationen finden Sie unter Sicherheit auf Zeilenebene .
Daten durch Verschlüsselung schützen
Schützen Sie Daten im Ruhezustand, während der Übertragung und während der Verwendung, ohne die Datenbankleistung zu beeinträchtigen. Weitere Informationen finden Sie unter SQL Server-Verschlüsselung .
Verschlüsselung ruhender Daten Verwenden Sie zum Schutz personenbezogener Daten vor Offline-Medienangriffen auf der physischen Speicherebene die Verschlüsselung ruhender Daten, auch Transparent Data Encryption (TDE) genannt. Das bedeutet, dass Ihre Daten auch dann geschützt sind, wenn die physischen Medien gestohlen oder unsachgemäß entsorgt werden. TDE führt die Verschlüsselung und Entschlüsselung von Datenbanken, Sicherungen und Transaktionsprotokollen in Echtzeit durch, ohne dass Änderungen an Ihren Anwendungen erforderlich sind.
Verschlüsselung während der Übertragung Zum Schutz vor Snooping und „Man-in-the-Middle-Angriffen" können Sie über das Netzwerk übertragene Daten verschlüsseln. SQL Server unterstützt Transport Layer Security (TLS) 1.2 für hochsichere Kommunikation. Das Tabular Data Stream (TDS)-Protokoll wird auch verwendet, um die Kommunikation über nicht vertrauenswürdige Netzwerke zu schützen.
Verwendete Verschlüsselung auf dem Client Um persönliche Daten während der Nutzung zu schützen, ist „Always Encrypted" die gewünschte Funktion. Personenbezogene Daten werden von einem Treiber auf dem Client-Computer verschlüsselt und entschlüsselt, ohne dass Verschlüsselungsschlüssel an die Datenbank-Engine weitergegeben werden. Infolgedessen sind verschlüsselte Daten nur für die Personen sichtbar, die für die Verwaltung dieser Daten verantwortlich sind, und nicht für andere hochprivilegierte Benutzer, die keinen Zugriff haben sollten. Je nach ausgewähltem Verschlüsselungstyp kann Always Encrypted einige Datenbankfunktionen wie Suchen, Gruppieren und Indizieren von verschlüsselten Spalten einschränken.
Umgang mit Datenschutzbedenken
Datenschutzbedenken sind so weit verbreitet, dass die Europäische Union mit der Datenschutz-Grundverordnung (DSGVO) gesetzliche Vorgaben definiert hat. Glücklicherweise ist ein SQL Server-Backend gut geeignet, um auf diese Anforderungen einzugehen. Stellen Sie sich die Implementierung der DSGVO in einem dreistufigen Rahmen vor.

Schritt 1: Bewerten und verwalten Sie das Compliance-Risiko
Die DSGVO verlangt, dass Sie die persönlichen Informationen, die Sie in Tabellen und Dateien haben, identifizieren und inventarisieren. Bei diesen Informationen kann es sich um einen Namen, ein Foto, eine E-Mail-Adresse, Bankdaten, Beiträge auf Websites sozialer Netzwerke, medizinische Informationen oder sogar eine IP-Adresse handeln.
Ein neues Tool, SQL Data Discovery and Classification , das in SQL Server Management Studio integriert ist, hilft Ihnen, vertrauliche Daten zu erkennen, zu klassifizieren, zu kennzeichnen und zu melden, indem zwei Metadatenattribute auf Spalten angewendet werden:
Labels Um die Sensibilität von Daten zu definieren.
Informationstypen Um zusätzliche Granularität über die in einer Spalte gespeicherten Datentypen bereitzustellen.
Ein weiterer Erkennungsmechanismus, den Sie verwenden können, ist die Volltextsuche, die die Verwendung von CONTAINS- und FREETEXT-Prädikaten und Rowset-Wert-Funktionen wie CONTAINSTABLE und FREETEXTTABLE zur Verwendung mit der SELECT-Anweisung umfasst. Mit der Volltextsuche können Sie Tabellen durchsuchen, um Wörter, Wortkombinationen oder Variationen eines Wortes wie Synonyme oder Flexionsformen zu entdecken. Weitere Informationen finden Sie unter Volltextsuche .
Schritt 2: Persönliche Daten schützen
Die DSGVO verlangt von Ihnen, personenbezogene Daten zu sichern und den Zugriff darauf zu beschränken. Zusätzlich zu den Standardschritten, die Sie unternehmen, um den Zugriff auf Ihr Netzwerk und Ihre Ressourcen zu verwalten, wie z. B. Firewall-Einstellungen, können Sie die Sicherheitsfunktionen von SQL Server verwenden, um den Datenzugriff zu kontrollieren:
SQL Server-Authentifizierung, um die Benutzeridentität zu verwalten und unbefugten Zugriff zu verhindern.
Sicherheit auf Zeilenebene, um den Zugriff auf Zeilen in einer Tabelle basierend auf der Beziehung zwischen dem Benutzer und diesen Daten zu beschränken.
Dynamische Datenmaskierung, um die Exposition gegenüber personenbezogenen Daten zu begrenzen, indem sie vor nicht privilegierten Benutzern maskiert werden.
Verschlüsselung, um sicherzustellen, dass personenbezogene Daten während der Übertragung und Speicherung geschützt und vor Kompromittierung geschützt sind, auch auf Serverseite.
Weitere Informationen finden Sie unter SQL Server-Sicherheit .
Schritt 3: Reagieren Sie effizient auf Anfragen
Die DSGVO verlangt, dass Sie Aufzeichnungen über die Verarbeitung personenbezogener Daten führen und diese Aufzeichnungen den Aufsichtsbehörden auf Anfrage zur Verfügung stellen. Wenn Probleme wie die versehentliche Veröffentlichung von Daten auftreten, können Sie mit Schutzkontrollen schnell reagieren. Daten müssen schnell verfügbar sein, wenn Berichte benötigt werden. Beispielsweise verlangt die DSGVO, dass eine Verletzung des Schutzes personenbezogener Daten der Aufsichtsbehörde „spätestens 72 Stunden nach Bekanntwerden" gemeldet wird.
SQL Server 2017 unterstützt Sie bei Berichterstellungsaufgaben auf verschiedene Weise:
Mit SQL Server Audit können Sie sicherstellen, dass dauerhafte Aufzeichnungen über Datenbankzugriffe und Verarbeitungsaktivitäten vorhanden sind. Es führt ein detailliertes Audit durch, das Datenbankaktivitäten verfolgt, damit Sie potenzielle Bedrohungen, mutmaßlichen Missbrauch oder Sicherheitsverletzungen verstehen und identifizieren können. Sie können problemlos Datenforensik durchführen.
Temporale SQL Server-Tabellen sind systemversionierte Benutzertabellen, die dafür ausgelegt sind, einen vollständigen Verlauf von Datenänderungen zu führen. Sie können diese für eine einfache Berichterstellung und Point-in-Time-Analyse verwenden.
Die SQL-Schwachstellenbewertung hilft Ihnen, Sicherheits- und Berechtigungsprobleme zu erkennen. Wenn ein Problem erkannt wird, können Sie auch einen Drilldown in Datenbank-Scan-Berichte durchführen, um Maßnahmen zur Lösung zu finden.
Weitere Informationen finden Sie unter Erstellen einer Plattform des Vertrauens (E-Book) und Journey to GDPR Compliance .
Erstellen Sie Datenbank-Snapshots
Ein Datenbank-Snapshot ist eine schreibgeschützte, statische Ansicht einer SQL Server-Datenbank zu einem bestimmten Zeitpunkt. Obwohl Sie eine Access-Datenbankdatei kopieren können, um effektiv einen Datenbank-Snapshot zu erstellen, verfügt Access nicht über eine integrierte Methode wie SQL Server. Sie können einen Datenbank-Snapshot zum Schreiben von Berichten verwenden, die auf den Daten zum Zeitpunkt der Erstellung des Datenbank-Snapshots basieren. Sie können auch einen Datenbank-Snapshot verwenden, um historische Daten zu verwalten, z. B. einen für jedes Finanzquartal, den Sie zum Rollup von Periodenendeberichten verwenden. Wir empfehlen die folgenden Best Practices:
Benennen Sie den Snapshot Jeder Datenbank-Snapshot erfordert einen eindeutigen Datenbanknamen. Fügen Sie dem Namen den Zweck und den Zeitrahmen hinzu, um die Identifizierung zu erleichtern. Um beispielsweise dreimal am Tag in 6-Stunden-Intervallen zwischen 6:00 und 18:00 Uhr einen Snapshot der AdventureWorks-Datenbank basierend auf einer 24-Stunden-Uhr zu erstellen, nennen Sie sie AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200 und AdventureWorks_snapshot_1800.
Begrenzen Sie die Anzahl der Snapshots Jeder Datenbank-Snapshot bleibt bestehen, bis er explizit gelöscht wird. Da jeder Snapshot weiter wächst, möchten Sie möglicherweise Speicherplatz sparen, indem Sie einen älteren Snapshot löschen, nachdem Sie einen neuen Snapshot erstellt haben. Wenn Sie beispielsweise tägliche Berichte erstellen, bewahren Sie den Datenbank-Snapshot 24 Stunden lang auf, löschen ihn dann und ersetzen ihn durch einen neuen.
Herstellen einer Verbindung mit dem richtigen Snapshot Um einen Datenbank-Snapshot verwenden zu können, muss das Access-Front-End den richtigen Speicherort kennen. Wenn Sie einen vorhandenen Snapshot durch einen neuen ersetzen, müssen Sie Access auf den neuen Snapshot umleiten. Fügen Sie dem Access-Front-End Logik hinzu, um sicherzustellen, dass Sie eine Verbindung mit dem richtigen Datenbank-Snapshot herstellen.
So erstellen Sie einen Datenbank-Snapshot:
CREATE DATABASE AdventureWorks_dbss1800 ON ( NAME = AdventureWorks_Data, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' ) AS SNAPSHOT OF AdventureWorks;Weitere Informationen finden Sie unter Datenbank-Snapshots (SQL Server) .
Parallelitätssteuerung
Wenn viele Personen gleichzeitig versuchen, Daten in einer Datenbank zu ändern, ist ein Kontrollsystem erforderlich, damit Änderungen, die von einer Person vorgenommen werden, die einer anderen Person nicht nachteilig beeinflussen. Dies wird als Parallelitätssteuerung bezeichnet, und es gibt zwei grundlegende Sperrstrategien, pessimistisch und optimistisch. Das Sperren kann Benutzer daran hindern, Daten auf eine Weise zu ändern, die andere Benutzer betrifft. Das Sperren trägt auch dazu bei, die Datenbankintegrität sicherzustellen, insbesondere bei Abfragen, die andernfalls zu unerwarteten Ergebnissen führen könnten. Es gibt wichtige Unterschiede in der Art und Weise, wie Access und SQL Server diese Parallelitätssteuerungsstrategien implementieren.
In Access ist die standardmäßige Sperrstrategie optimistisch und gewährt der ersten Person, die versucht, in einen Datensatz zu schreiben, den Besitz der Sperre. Access zeigt das Dialogfeld Schreibkonflikt für die andere Person an, die versucht, gleichzeitig in denselben Datensatz zu schreiben. Um den Konflikt zu lösen, kann die andere Person den Datensatz speichern, in die Zwischenablage kopieren oder die Änderungen löschen.
Sie können auch die RecordLocks- Eigenschaft verwenden, um die Parallelitätssteuerungsstrategie zu ändern. Diese Eigenschaft wirkt sich auf Formulare, Berichte und Abfragen aus und hat drei Einstellungen:
Keine Sperren In einem Formular können Benutzer versuchen, denselben Datensatz gleichzeitig zu bearbeiten, aber das Dialogfeld Schreibkonflikt wird möglicherweise angezeigt. In einem Bericht werden Datensätze nicht gesperrt, während der Bericht in der Vorschau angezeigt oder gedruckt wird. In einer Abfrage werden Datensätze nicht gesperrt, während die Abfrage ausgeführt wird. Dies ist die Access-Methode zum Implementieren von optimistischem Sperren.
Alle Datensätze Alle Datensätze in der zugrunde liegenden Tabelle oder Abfrage sind gesperrt, während das Formular in der Formularansicht oder Datenblattansicht geöffnet ist, während der Bericht in der Vorschau angezeigt oder gedruckt wird oder während die Abfrage ausgeführt wird. Benutzer können die Aufzeichnungen während der Sperre lesen.
Bearbeiteter Datensatz Bei Formularen und Abfragen wird eine Seite mit Datensätzen gesperrt, sobald ein Benutzer mit der Bearbeitung eines beliebigen Felds im Datensatz beginnt, und bleibt gesperrt, bis der Benutzer zu einem anderen Datensatz wechselt. Folglich kann ein Datensatz nur von einem Benutzer gleichzeitig bearbeitet werden. Dies ist die Access-Methode zum Implementieren von pessimistischem Sperren.
Weitere Informationen finden Sie unter Dialogfeld „Write Conflict" und „RecordLocks Property" .
In SQL Server funktioniert die Parallelitätssteuerung folgendermaßen:
Pessimistisch Nachdem ein Benutzer eine Aktion ausgeführt hat, die zur Anwendung einer Sperre führt, können andere Benutzer keine Aktionen ausführen, die mit der Sperre in Konflikt stehen würden, bis der Besitzer sie freigibt. Diese Parallelitätssteuerung wird hauptsächlich in Umgebungen verwendet, in denen es viele Datenkonkurrenzen gibt.
Optimistisch Bei der optimistischen Parallelitätssteuerung sperren Benutzer keine Daten, wenn sie sie lesen. Wenn ein Benutzer Daten aktualisiert, prüft das System, ob ein anderer Benutzer die Daten geändert hat, nachdem sie gelesen wurden. Wenn ein anderer Benutzer die Daten aktualisiert hat, wird ein Fehler ausgelöst. Normalerweise setzt der Benutzer, der den Fehler erhält, die Transaktion zurück und beginnt von vorne. Diese Gleichzeitigkeitssteuerung wird hauptsächlich in Umgebungen verwendet, in denen es wenig Konkurrenz um Daten gibt.
Sie können die Art der Parallelitätssteuerung angeben, indem Sie mehrere Transaktionsisolationsstufen auswählen, die die Schutzstufe für die Transaktion vor Änderungen durch andere Transaktionen definieren, indem Sie die Anweisung SET TRANSACTION verwenden:
SET TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SNAPSHOT | SERIALIZABLE }Isolationsstufe | Beschreibung |
Ungebunden lesen | Transaktionen werden nur so weit isoliert, dass sichergestellt ist, dass keine physisch beschädigten Daten gelesen werden. |
Lies engagiert | Transaktionen können Daten lesen, die zuvor von einer anderen Transaktion gelesen wurden, ohne auf den Abschluss der ersten Transaktion zu warten. |
Wiederholbares Lesen | Lese- und Schreibsperren treten für ausgewählte Daten bis zum Ende der Transaktion auf, aber Phantomlesevorgänge können auftreten. |
Schnappschuss | Verwendet die Zeilenversion, um Lesekonsistenz auf Transaktionsebene bereitzustellen. |
Serialisierbar | Transaktionen sind vollständig voneinander isoliert. |
Weitere Informationen finden Sie im Handbuch zu Transaktionssperren und Zeilenversionierung .
Verbessern Sie die Abfrageleistung
Sobald eine Access Pass-Through-Abfrage funktioniert, nutzen Sie die ausgefeilten Methoden, mit denen SQL Server sie effizienter ausführen kann.
Im Gegensatz zu einer Access-Datenbank stellt SQL Server parallele Abfragen bereit, um die Abfrageausführung und Indexvorgänge für Computer zu optimieren, die über mehr als einen Mikroprozessor (CPU) verfügen. Da SQL Server einen Abfrage- oder Indexvorgang mithilfe mehrerer Systemarbeitsthreads parallel ausführen kann, kann der Vorgang schnell und effizient abgeschlossen werden.
Abfragen sind eine entscheidende Komponente zur Verbesserung der Gesamtleistung Ihrer Datenbanklösung. Fehlerhafte Abfragen werden unbegrenzt ausgeführt, führen zu Zeitüberschreitungen und verbrauchen Ressourcen wie CPUs, Arbeitsspeicher und Netzwerkbanditen. Dies behindert die Verfügbarkeit kritischer Geschäftsinformationen. Selbst eine fehlerhafte Abfrage kann schwerwiegende Leistungsprobleme für Ihre Datenbank verursachen.
Weitere Informationen finden Sie unter Schnellere Abfragen mit SQL Server (E-Book) .
Abfrageoptimierung
Mehrere Tools arbeiten zusammen, um Ihnen zu helfen, die Leistung einer Abfrage zu analysieren und zu verbessern: Abfrageoptimierer, Ausführungspläne und Abfragespeicher.
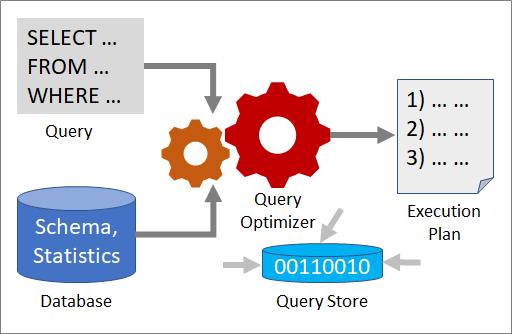
Abfrageoptimierer
Der Abfrageoptimierer ist eine der wichtigsten Komponenten von SQL Server. Verwenden Sie den Abfrageoptimierer, um eine Abfrage zu analysieren und die effizienteste Methode für den Zugriff auf die erforderlichen Daten zu ermitteln. Die Eingabe für den Abfrageoptimierer besteht aus der Abfrage, dem Datenbankschema (Tabellen- und Indexdefinitionen) und Datenbankstatistiken. Die Ausgabe des Abfrageoptimierers ist ein Ausführungsplan.
Weitere Informationen finden Sie unter Der SQL Server-Abfrageoptimierer .
Ausführungsplan
Ein Ausführungsplan ist eine Definition, die die Quelltabellen, auf die zugegriffen werden soll, und die Methoden, die zum Extrahieren von Daten aus jeder Tabelle verwendet werden, sequenziert. Optimierung ist der Prozess der Auswahl eines Ausführungsplans aus potenziell vielen möglichen Plänen. Jeder mögliche Ausführungsplan ist mit Kosten in Höhe der verwendeten Rechenressourcen verbunden, und der Abfrageoptimierer wählt den Plan mit den niedrigsten geschätzten Kosten aus.
SQL Server muss sich auch dynamisch an sich ändernde Bedingungen in der Datenbank anpassen. Regressionen in Abfrageausführungsplänen können sich stark auf die Leistung auswirken. Bestimmte Änderungen in einer Datenbank können dazu führen, dass ein Ausführungsplan basierend auf dem neuen Status der Datenbank entweder ineffizient oder ungültig wird. SQL Server erkennt die Änderungen, die einen Ausführungsplan ungültig machen, und markiert den Plan als ungültig.
Für die nächste Verbindung, die die Abfrage ausführt, muss dann ein neuer Plan neu kompiliert werden. Zu den Bedingungen, die einen Plan ungültig machen, gehören:
Änderungen an einer Tabelle oder Ansicht, auf die von der Abfrage verwiesen wird (ALTER TABLE und ALTER VIEW).
Änderungen an Indizes, die vom Ausführungsplan verwendet werden.
Aktualisierungen der vom Ausführungsplan verwendeten Statistiken, die entweder explizit von einer Anweisung wie UPDATE STATISTICS oder automatisch generiert werden.
Weitere Informationen finden Sie unter Ausführungspläne .
Abfragespeicher
Der Abfragespeicher bietet Einblicke in die Auswahl und Leistung von Ausführungsplänen. Es vereinfacht die Fehlerbehebung bei der Leistung, indem es Ihnen hilft, Leistungsunterschiede, die durch Änderungen des Ausführungsplans verursacht wurden, schnell zu finden. Der Abfragespeicher sammelt Telemetriedaten, z. B. einen Abfrageverlauf, Pläne, Laufzeitstatistiken und Wartestatistiken. Verwenden Sie die ALTER DATABASE-Anweisung, um den Abfragespeicher zu implementieren:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;Weitere Informationen finden Sie unter Leistungsüberwachung mithilfe des Abfragespeichers .
Automatische Plankorrektur
Die vielleicht einfachste Möglichkeit zur Verbesserung der Abfrageleistung ist die automatische Plankorrektur, eine Funktion, die in Azure SQL-Datenbank verfügbar ist. Sie schalten es einfach ein und lassen es arbeiten. Es führt kontinuierlich eine Ausführungsplanüberwachung und -analyse durch, erkennt problematische Ausführungspläne und behebt automatisch Leistungsprobleme. Hinter den Kulissen verwendet die automatische Plankorrektur eine vierstufige Strategie aus Lernen, Anpassen, Verifizieren und Wiederholen.
Weitere Informationen finden Sie unter Automatisches Tuning .
Adaptive Abfrageverarbeitung
Sie können auch schnellere Abfragen erhalten, indem Sie einfach auf SQL Server 2017 aktualisieren, das über eine neue Funktion namens adaptive Abfrageverarbeitung verfügt. SQL Server passt Abfrageplanauswahlen basierend auf Laufzeitmerkmalen an.
Die Kardinalitätsschätzung nähert sich der Anzahl der Zeilen an, die bei jedem Schritt in einem Ausführungsplan verarbeitet werden. Ungenaue Schätzungen können zu einer langsamen Antwortzeit auf Abfragen, unnötiger Ressourcennutzung (Arbeitsspeicher, CPU und E/A) und reduziertem Durchsatz und Parallelität führen. Drei Techniken werden verwendet, um sich an die Workload-Eigenschaften der Anwendung anzupassen:
Feedback zur Arbeitsspeicherzuweisung im Stapelmodus Schlechte Kardinalitätsschätzungen können dazu führen, dass Abfragen „auf die Festplatte überlaufen" oder zu viel Arbeitsspeicher beanspruchen. SQL Server 2017 passt Speicherzuweisungen basierend auf Ausführungsfeedback an, entfernt Überläufe auf den Datenträger und verbessert die Parallelität für sich wiederholende Abfragen.
Adaptive Joins im Stapelmodus Adaptive Joins wählen während der Laufzeit basierend auf den tatsächlichen Eingabezeilen dynamisch einen besseren internen Join-Typ (Need Loop Joins, Merge Joins oder Hash Joins) aus. Folglich kann ein Plan während der Ausführung dynamisch zu einer besseren Join-Strategie wechseln.
Verschachtelte Ausführung Tabellenwertfunktionen mit mehreren Anweisungen wurden traditionell von der Abfrageverarbeitung als Black Box behandelt. SQL Server 2017 kann die Anzahl der Zeilen besser schätzen, um nachgelagerte Vorgänge zu verbessern.
Sie können Workloads automatisch für die adaptive Abfrageverarbeitung qualifizieren, indem Sie einen Kompatibilitätsgrad von 140 für die Datenbank aktivieren:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;Weitere Informationen finden Sie unter Intelligente Abfrageverarbeitung in SQL-Datenbanken .
Möglichkeiten zur Abfrage
In SQL Server gibt es mehrere Abfragemöglichkeiten, und jede hat ihre Vorteile. Sie möchten wissen, welche das sind, damit Sie die richtige Wahl für Ihre Access-Lösung treffen können. Am besten erstellen Sie Ihre TSQL-Abfragen, indem Sie sie interaktiv bearbeiten und testen, indem Sie den Transact-SQL-Editor von SQL Server Management Studio (SSMS) verwenden , der über Intellisense verfügt, um Sie bei der Auswahl der richtigen Schlüsselwörter und der Überprüfung auf Syntaxfehler zu unterstützen.
Ansichten
In SQL Server ist eine Ansicht wie eine virtuelle Tabelle, bei der die Ansichtsdaten aus einer oder mehreren Tabellen oder anderen Ansichten stammen. Ansichten werden jedoch genau wie Tabellen in Abfragen referenziert. Ansichten können die Komplexität von Abfragen verbergen und zum Schutz von Daten beitragen, indem sie den Satz von Zeilen und Spalten einschränken. Hier ist ein Beispiel für eine einfache Ansicht:
CREATE VIEW HumanResources.EmployeeHireDate AS SELECT p.FirstName, p.LastName, e.HireDate FROM HumanResources.Employee AS e JOIN Person.Person AS p ON e.BusinessEntityID = p.BusinessEntityID;Erstellen Sie für eine optimale Leistung und zum Bearbeiten der Ansichtsergebnisse eine indizierte Ansicht, die wie eine Tabelle in der Datenbank verbleibt, ihr Speicherplatz zugewiesen wird und wie jede Tabelle abgefragt werden kann. Um es in Access zu verwenden, verknüpfen Sie die Ansicht auf die gleiche Weise wie mit einer Tabelle. Hier ist ein Beispiel für eine indizierte Ansicht:
CREATE VIEW Sales.vOrders WITH SCHEMABINDING AS SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue, OrderDate, ProductID, COUNT_BIG(*) AS COUNT FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o WHERE od.SalesOrderID = o.SalesOrderID GROUP BY OrderDate, ProductID; CREATE UNIQUE CLUSTERED INDEX IDX_V1 ON Sales.vOrders (OrderDate, ProductID);Es gibt jedoch Einschränkungen. Sie können keine Daten aktualisieren, wenn mehr als eine Basistabelle betroffen ist oder die Ansicht Aggregatfunktionen oder eine DISTINCT-Klausel enthält. Wenn SQL Server eine Fehlermeldung zurückgibt, die besagt, dass es nicht weiß, welcher Datensatz gelöscht werden soll, müssen Sie möglicherweise einen Löschauslöser für die Ansicht hinzufügen. Schließlich können Sie die ORDER BY-Klausel nicht wie bei einer Access-Abfrage verwenden.
Weitere Informationen finden Sie unter Ansichten und indizierte Ansichten erstellen .
Gespeicherte Prozeduren
Eine gespeicherte Prozedur ist eine Gruppe von einer oder mehreren TSQL-Anweisungen, die Eingabeparameter übernehmen, Ausgabeparameter zurückgeben und Erfolg oder Fehler mit einem Statuswert anzeigen. Sie fungieren als Zwischenschicht zwischen dem Access-Front-End und dem SQL Server-Back-End. Gespeicherte Prozeduren können so einfach wie eine SELECT-Anweisung oder so komplex wie ein beliebiges Programm sein. Hier ist ein Beispiel:
CREATE PROCEDURE HumanResources.uspGetEmployees @LastName nvarchar(50), @FirstName nvarchar(50) AS SET NOCOUNT ON; SELECT FirstName, LastName, Department FROM HumanResources.vEmployeeDepartmentHistory WHERE FirstName = @FirstName AND LastName = @LastName AND EndDate IS NULL;Wenn Sie eine gespeicherte Prozedur in Access verwenden, gibt sie normalerweise eine Ergebnismenge an ein Formular oder einen Bericht zurück. Es kann jedoch andere Aktionen ausführen, die keine Ergebnisse zurückgeben, z. B. DDL- oder DML-Anweisungen. Wenn Sie eine Pass-Through-Abfrage verwenden, stellen Sie sicher, dass Sie die Eigenschaft „ Return Records " entsprechend festlegen.
Weitere Informationen finden Sie unter Gespeicherte Prozeduren .
Allgemeine Tabellenausdrücke
Ein Common Table Expressions (CTE) ist wie eine temporäre Tabelle, die eine benannte Ergebnismenge generiert. Es existiert nur für die Ausführung einer einzelnen Abfrage oder DML-Anweisung. Ein CTE wird in derselben Codezeile erstellt wie die SELECT-Anweisung oder die DML-Anweisung, die es verwendet, während das Erstellen und Verwenden einer temporären Tabelle oder Ansicht normalerweise ein zweistufiger Prozess ist. Hier ist ein Beispiel:
-- Define the CTE expression name and column list. WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear) AS -- Define the CTE query. ( SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear FROM Sales.SalesOrderHeader WHERE SalesPersonID IS NOT NULL ) -- Define the outer query referencing the CTE name. SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear FROM Sales_CTE GROUP BY SalesYear, SalesPersonID ORDER BY SalesPersonID, SalesYear;Ein CTE hat mehrere Vorteile, einschließlich der folgenden:
Da CTEs vorübergehend sind, müssen Sie sie nicht wie Ansichten als permanente Datenbankobjekte erstellen.
Sie können in einer Abfrage oder DML-Anweisung mehr als einmal auf denselben CTE verweisen, wodurch Ihr Code übersichtlicher wird.
Sie können Abfragen verwenden, die auf einen CTE verweisen, um einen Cursor zu definieren.
Weitere Informationen finden Sie unter WITH common_table_expression .
Benutzerdefinierte Funktionen
Eine benutzerdefinierte Funktion (UDF) kann Abfragen und Berechnungen durchführen und entweder Skalarwerte oder Datenergebnissätze zurückgeben. Sie sind wie Funktionen in Programmiersprachen, die Parameter akzeptieren, eine Aktion wie eine komplexe Berechnung ausführen und das Ergebnis dieser Aktion als Wert zurückgeben. Hier ist ein Beispiel:
CREATE FUNCTION dbo.ISOweek (@DATE datetime) RETURNS int WITH SCHEMABINDING -- Helps improve performance WITH EXECUTE AS CALLER AS BEGIN DECLARE @ISOweek int; SET @ISOweek= DATEPART(wk,@DATE)+1 -DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104'); -- Special cases: Jan 1-3 may belong to the previous year IF (@ISOweek=0) SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1 AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1; -- Special case: Dec 29-31 may belong to the next year IF ((DATEPART(mm,@DATE)=12) AND ((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28)) SET @ISOweek=1; RETURN(@ISOweek); END; GO SET DATEFIRST 1; SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';Eine UDF hat bestimmte Einschränkungen. Beispielsweise können sie bestimmte nichtdeterministische Systemfunktionen nicht verwenden, DML- oder DDL-Anweisungen ausführen oder dynamische SQL-Abfragen durchführen.
Weitere Informationen finden Sie unter Benutzerdefinierte Funktionen .
Fügen Sie Schlüssel und Indizes hinzu
Unabhängig davon, welches Datenbanksystem Sie verwenden, gehen Schlüssel und Indizes Hand in Hand.
Schlüssel
Stellen Sie in SQL Server sicher, dass Sie Primärschlüssel für jede Tabelle und Fremdschlüssel für jede zugehörige Tabelle erstellen. Das äquivalente Feature in SQL Server zum Access AutoNumber-Datentyp ist die IDENTITY-Eigenschaft, die zum Erstellen von Schlüsselwerten verwendet werden kann. Sobald Sie diese Eigenschaft auf eine beliebige numerische Spalte anwenden, wird sie schreibgeschützt und vom Datenbanksystem verwaltet. Wenn Sie einen Datensatz in eine Tabelle einfügen, die eine IDENTITY-Spalte enthält, erhöht das System automatisch den Wert für die IDENTITY-Spalte um 1 und beginnt bei 1, aber Sie können diese Werte mit Argumenten steuern.
Weitere Informationen finden Sie unter CREATE TABLE, IDENTITY (Eigenschaft) .
Indizes
Wie immer ist die Auswahl der Indizes ein Balanceakt zwischen Abfragegeschwindigkeit und Aktualisierungskosten. In Access haben Sie einen Indextyp, aber in SQL Server haben Sie zwölf. Glücklicherweise können Sie den Abfrageoptimierer verwenden, um zuverlässig den effektivsten Index auszuwählen. Und in Azure SQL können Sie die automatische Indexverwaltung verwenden, ein Feature der automatischen Optimierung, das das Hinzufügen oder Entfernen von Indizes für Sie empfiehlt. Im Gegensatz zu Access müssen Sie in SQL Server Ihre eigenen Indizes für Fremdschlüssel erstellen. Sie können auch Indizes für eine indizierte Ansicht erstellen, um die Abfrageleistung zu verbessern. Der Nachteil einer indizierten Sicht ist der erhöhte Overhead, wenn Sie Daten in den Basistabellen der Sicht ändern, da die Sicht ebenfalls aktualisiert werden muss. Weitere Informationen finden Sie unter Architektur- und Designleitfaden für SQL Server- Indizes und Indizes .
Transaktionen durchführen
Die Durchführung eines Online-Transaktionsprozesses (OLTP) ist schwierig, wenn Sie Access verwenden, aber relativ einfach mit SQL Server. Eine Transaktion ist eine einzelne Arbeitseinheit, die alle Datenänderungen festschreibt, wenn sie erfolgreich ist, aber die Änderungen rückgängig macht, wenn sie nicht erfolgreich ist. Eine Transaktion muss vier Eigenschaften haben, die oft als ACID bezeichnet werden:
Atomicity A transaction must be an atomic unit of work; either all its data modifications are performed, or none are performed.
Consistency When completed, a transaction must leave all data in a consistent state. This means all data integrity rules are applied.
Isolation Changes made by concurrent transactions are isolated from the current transaction.
Durability After a transaction has completed, changes are permanent even in the event of a system failure.
You use a transaction to ensure guaranteed data integrity, such as an ATM cash withdrawal or automatic deposit of a paycheck. You can do explicit, implicit, or batch-scoped transactions. Here are two, TSQL examples:
-- Using an explicit transaction BEGIN TRANSACTION; DELETE FROM HumanResources.JobCandidate WHERE JobCandidateID = 13; COMMIT; -- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists. CREATE TABLE ValueTable (id int); BEGIN TRANSACTION; INSERT INTO ValueTable VALUES(1); INSERT INTO ValueTable VALUES(2); ROLLBACK;For more information, see Transactions .
Using constraints and triggers
All databases have ways to maintain data integrity.
Constraints
In Access, you enforce referential integrity in a table relationship through foreign key-primary key pairings, cascading updates and deletes, and validation rules. For more information, see Guide to table relationships and Restrict data input by using validation rules .
In SQL Server, you use UNIQUE and CHECK constraints, which are database objects that enforce data integrity in SQL Server tables. To validate that a value is valid in another table, use a foreign key constraint. To validate that a value in a column is within a specific range, use a check constraint. These objects are your first line of defense and are designed to work efficiently. For more information, see Unique Constraints and Check Constraints .
Triggers
Access does not have database triggers. In SQL Server, you can use triggers to enforce complex data integrity rules and to run this business logic on the server. A database trigger is a stored procedure that runs when specific actions occur within a database. The trigger is an event, such as adding or deleting a record to a table, that fires and then executes the stored procedure. Although an Access database can ensure referential integrity when a user attempts to update or delete data, SQL Server has a sophisticated set of triggers. For example, you can program a trigger to delete records in bulk and ensure data integrity. You can even add triggers to tables and views.
For more information, see Triggers - DML , Triggers - DDL and Designing a T-SQL trigger .
Use computed columns
In Access, you create a calculated column by adding it to a query and building an expression, such as:
Extended Price: [Quantity] * [Unit Price]In SQL Server, the equivalent feature is called a computed column, which is a virtual column that is not physically stored in the table, unless the column is marked PERSISTED. Like a calculated column, a computed column uses data from other columns in an expression. To create a computed column, add it to a table. Zum Beispiel:
CREATE TABLE dbo.Products ( ProductID int IDENTITY (1,1) NOT NULL , QtyAvailable smallint , UnitPrice money , InventoryValue AS QtyAvailable * UnitPrice );For more information, see Specify Computed Columns in a Table .
Time stamp your data
You sometimes add a table field to record a time stamp when a record is created so you can log the data entry. In Access, you can simply create a date column with the default value of =Now() . To record a date or time in SQL Server, use the datetime2 data type with the default value of SYSDATETIME() .
Note Avoid confusing rowversion with adding a timestamp to your data. The keyword timestamp is a synonym for rowversion in SQL Server, but you should use the keyword rowversion. In SQL Server, rowversion is a data type that exposes automatically generated, unique binary numbers within a database, and is generally used as a mechanism for version-stamping table rows. However, the rowversion data type is just an incrementing number, does not preserve a date or a time, and is not designed for timestamping a row.
For more information, see rowversion . For more information about using rowversion to minimize record conflicts, see Migrate an Access database to SQL Server .
Manage large objects
In Access you manage unstructured data, such as files, photos, and images, by using the Attachment data type . In SQL Server terminology, unstructured data is called a Blob (Binary Large Object) and there are several ways to work with them:
FILESTREAM Uses the varbinary(max) data type to store the unstructured data on the file system rather than the database. For more information, see Access FILESTREAM Data with Transact-SQL .
FileTable Stores blobs in special tables called FileTables and provides compatibility with Windows applications as if they were stored in the file system and without making any changes to your client applications. FileTable requires the use of FILESTREAM. For more information, see FileTables .
Remote BLOB store (RBS) Stores binary large objects (BLOBs) in commodity storage solutions instead of directly on the server. This saves space and reduces hardware resources. For more information, see Binary Large Object (Blob) Data .
Work with hierarchical data
Although relational databases such as Access are very flexible, working with hierarchical relationships is an exception and often requires complex SQL statements or code. Examples of hierarchical data include: an organizational structure, a file system, a taxonomy of language terms, and a graph of links between Web pages. SQL Server has a built-in hierarchyid data type and set of hierarchical functions to easily store, query, and manage hierarchical data.
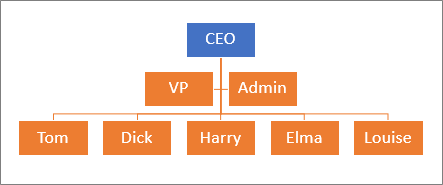
For more information, see Hierarchical data and Tutorial: Using the hierarchyid data type .
Manipulate JSON text
JavaScript Object Notation (JSON) is a web service that uses human-readable text to transmit data as attribute–value pairs in asynchronous browser–server communication. Zum Beispiel:
{ "firstName": "Mary", "lastName": "Contrary", "spouse": null, "age": 27 }Access does not have any built-in ways to manager JSON data, but in SQL Server you can smoothly store, index, query, and extract JSON data. You can convert and store JSON text in a table or format data as JSON text. For example, you may want to format query results as JSON for a Web app or add JSON data structures into rows and columns.
Note JSON is not supported in VBA. As an alternative, you can use XML in VBA by using the MSXML library.
For more information, see JSON data in SQL Server .
Resources
Now is a great time to learn more about SQL Server and Transact SQL (TSQL). As you've seen, there are many features like Access, but also capabilities Access simply doesn't have. To take your excursion to the next level, here are some learning resources:
Resource | Beschreibung |
Video-based course | |
Ttutorials about SQL Server 2017 | |
Hands on learning for Azure | |
Become an expert | |
The main landing page | |
Help information | |
Help information | |
An overview of the cloud | |
A visual summary of new features | |
A summary of features by versions | |
Download SQL Server Express 2017 | |
Download sample databases |
No comments:
Post a Comment